# BFS 算法解题套路框架
在说 BFS 框架之前我们先说 DFS 框架,其实 DFS 算法就是回溯算法 。我们前文「回溯算法框架套路详解」就已经详细解释了回溯算法的解题套路框架。
再说回 BFS,BFS 的核心思想应该不难理解,就是把一些问题抽象成图,从一个点开始,向四周开始扩散。一般来说,我们写 BFS 算法都适用「队列」这种数据结构,每次将一个节点周围的所有节点加入队列。
BFS 相对 DFS 的最主要区别是: BFS 找到的路径一定是最短的,但代价就是空间复杂度比 DFS 大很多 ,至于为什么,后面我们介绍框架就很容易看出来。
本文就由浅到深讲解两道 BFS 的典型题目:「二叉树的最小高度」和「打开密码锁的最少步数」,手把手教你写 BFS 算法。
# 算法框架
要说框架的话,我们先举例一下 BFS 出现的常见场景:
问题的本质就是让你在一幅「图」中找到从起点 start 到终点 target 的最近距离。 这个例子听起来很枯燥,但是 BFS 算法问题其实都是在干这个事儿,把枯燥的本质搞清楚了,再去欣赏各种问题的包装才能胸有成竹。
这个广义的描述可以有各种变体,比如走迷宫,有的格子是围墙不能走,从起点到终点的最短距离是多少?如果这个迷宫带「传送门」可以瞬间传送呢?
再比如说两个单词,要求你通过某些替换,把其中一个变成另一个,每次只能替换一个字符,最少要替换几次?
这些问题都没啥奇技淫巧,本质上就是一幅「图」,让你从一个起点,走到终点,问最短路径,这就是 BFS 的本质,框架搞清楚了直接默写就好。
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj())
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
队列 q 就不说了,BFS 的核心数据结构;cur.ajd() 泛指 cur 相邻的节点,比如说二维数组中,cur 上下左右四个位置就是相邻节点;visited 的主要作用是防止走回头路,大部分时候都是需要的,但是像二叉树结构中,子节点没有指向父节点的指针,不会走回头路时就不需要 visited。
# 二叉树的最小高度
我们先来个简单的问题实践一下 BFS 框架, 判断一棵二叉树的最小高度 (opens new window) :
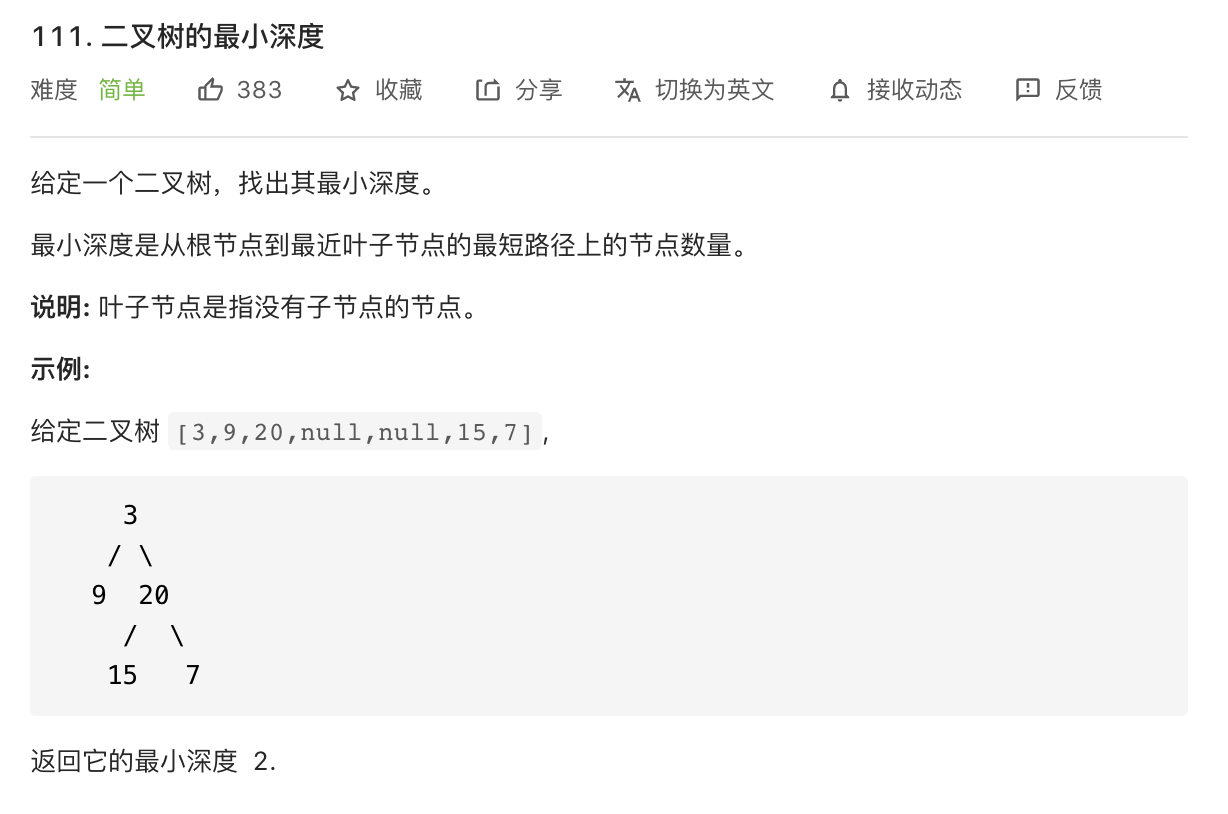
怎么套到 BFS 的框架中呢?首先要明确起点 start 和终点 target 是什么,怎么判断到达了终点?
显然起点就是根节点 root,终点就是最靠近根节点的那个「叶子节点」 ,叶子节点就是两个字节点都是 null 的节点:
if(cur.left === null && cur.right === null)
// 到达叶子节点
那么按照我们上述的框架稍加改造来写解法即可:
function minDepth(root: TreeNode | null): number {
if(!root) return 0
const q: TreeNode[] = [root]
// root本身就是一层,depth初始化为1
let depth = 1
while(!!q.length) {
const size = q.length
// 将当前队列中的所有节点向四周扩散
for(let i = 0; i < size; i++) {
const cur = q.shift()
// 判断是否到达终点
if(cur.left === null && cur.right === null) return depth
// 将 cur 的相邻节点加入队列
if(cur.left !== null) q.push(cur.left)
if(cur.right !== null) q.push(cur.right)
}
// 这里增加步数
depth++
}
return depth
}
二叉树是很简单的数据结构,我想上述代码你应该可以理解的吧,其实其他复杂问题都是这个框架的变形,在探讨复杂问题之前,我们解答两个问题:
为什么 BFS 可以找到最短距离,DFS 不行?
首先我们看看 BFS 的逻辑,depth 每增加一次,队列中的所有节点都向前迈一步,这保证了第一次到达终点时,走的步数是最少的。
DFS 不能找最短路径?其实也是可以的,但是时间复杂度相对高很多,DFS 实际上是靠递归堆栈记录走过的路径,你要找到最短路径,肯定得把二叉树中所有树杈都探索完才能对比出最短的路径有多长,而 BFS 借助队列做到一次一步「齐头并进」,是可以在不遍历完整棵树的条件下找到最短距离。
形象点说,DFS 是线,BFS 是面;DFS 是单打独斗,BFS 是集体行动。
既然 BFS 那么好,为啥 DFS 还要存在?
BFS 可以找到最短距离,但是空间复杂度高,而 DFS 的空间复杂度较低。
还是那刚才我们处理二叉树问题作为例子,假设给你的这棵二叉树是满二叉树,节点数为 N,对于 DFS 算法来说,空间复杂度无非就是递归堆栈,最坏情况下顶多就是树的高度,也就是
O(logN)。但是你想想 BFS 算法,队列中每次都会储存二叉树一层的节点,这样的话最坏的情况下空间复杂度应该是树的最底层节点的数量,也就是
N / 2,即O(N)。
由此可见,BFS 还是有代价的,一般来说在找最短路径的时候使用 BFS,其他时候还是 DFS 用的更多一些(主要是递归更好实现)。
好了,现在你对 BFS 了解的已经足够多了,下面来一道难一点的题目,深化一下框架的理解。
# 解开密码锁的最少次数
这是 LeetCode 原题, 打开转盘锁 (opens new window) :

题目中描述的就是生活中常见的密码锁,若没有任何约束,最少的波动次数很好酸,就像我们平时开密码锁那样直奔密码就可以了。
但现在难点在于,不能出现 deadends,应该如何计算最少波动次数呢?
第一步,我们不管所有限制条件,不管 deadends 和 target 的限制,就思考一个问题:如果让你设计一个算法,穷举所有可能的密码组合,你怎么做?
穷举呗,再简单一点,如果你只转一下锁,有几种可能?总共有 4 个位置,每个位置可以向上或者向下转,也就是有 8 种可能。
然后再以这 8 种密码作为基础,对每个密码再转一次,穷举出所有可能。
仔细想想,这就可以抽象成一幅图,每个节点有 8 个相邻的节点 ,又让你求最短距离,这不就是典型的 BFS 嘛,框架就可以派上用场了,先写出一个简陋的框架:
// 将 s[j] 向上拨动一次
String plusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '9')
ch[j] = '0';
else
ch[j] += 1;
return new String(ch);
}
// 将 s[i] 向下拨动一次
String minusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '0')
ch[j] = '9';
else
ch[j] -= 1;
return new String(ch);
}
// BFS 框架,打印出所有可能的密码
void BFS(String target) {
Queue<String> q = new LinkedList<>();
q.offer("0000");
while (!q.isEmpty()) {
int sz = q.size();
/* 将当前队列中的所有节点向周围扩散 */
for (int i = 0; i < sz; i++) {
String cur = q.poll();
/* 判断是否到达终点 */
System.out.println(cur);
/* 将一个节点的相邻节点加入队列 */
for (int j = 0; j < 4; j++) {
String up = plusOne(cur, j);
String down = minusOne(cur, j);
q.offer(up);
q.offer(down);
}
}
/* 在这里增加步数 */
}
return;
}
PS:这段代码当然有很多问题,但是我们做算法肯定不是一蹴而就,而是从简陋到完美。
这段 BFS 代码已经能够穷举所有可能的密码组合了,但是显然不能完成题目,有如下问题需要解决:
- 会走回头路。比如我们从“0000”拨到“1000”,但是下一步时还会拨回”0000“,这样的话会产生死循环;
- 没有终止条件,按照题目要求,我们找到 target 就应该结束并返回拨动的次数;
- 没有对 deadends 的处理,按道理这些「死亡密码」是不能出现的,也就是说你遇到这些密码是需要跳过的。
现在只需要按照修复上述问题即可:
int openLock(String[] deadends, String target) {
// 记录需要跳过的死亡密码
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
// 记录已经穷举过的密码,防止走回头路
Set<String> visited = new HashSet<>();
Queue<String> q = new LinkedList<>();
// 从起点开始启动广度优先搜索
int step = 0;
q.offer("0000");
visited.add("0000");
while (!q.isEmpty()) {
int sz = q.size();
/* 将当前队列中的所有节点向周围扩散 */
for (int i = 0; i < sz; i++) {
String cur = q.poll();
/* 判断是否到达终点 */
if (deads.contains(cur))
continue;
if (cur.equals(target))
return step;
/* 将一个节点的未遍历相邻节点加入队列 */
for (int j = 0; j < 4; j++) {
String up = plusOne(cur, j);
if (!visited.contains(up)) {
q.offer(up);
visited.add(up);
}
String down = minusOne(cur, j);
if (!visited.contains(down)) {
q.offer(down);
visited.add(down);
}
}
}
/* 在这里增加步数 */
step++;
}
// 如果穷举完都没找到目标密码,那就是找不到了
return -1;
}
至此,我们就解决了这道题目,有一个比较小的优化:可以不需要 dead 这个哈希集合,可以直接将这些元素初始化到 visited 集合中,效果是一样的,可以更加优雅。
# 双向 BFS 优化
你以为 BFS 到此为止了?恰恰相反,BFS 还有一种稍微高级一点的优化思路: 双向 BFS ,可以进一步提高算法的效率。
篇幅所限:这里就提一点区别: 传统的 BFS 框架就是从起点开始向四周扩散,遇到终点时停止;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集时停止。
不过双向 BFS 也是有局限的,因为你必须知道终点在哪。